In this era of technological advancement, we are producing data like never before. Let’s take for eg. Large Hadron Collider wherein we are producing data at the rate of 1 PB per second. Given we are producing these amounts of data, we require efficient data storage formats which can provide:
- High compression ratios for data containing multiple fields
- High read throughput for analytics use cases.
Parquet is an accepted solution worldwide to provide these guarantees. Parquet provides better compression ratio as well as better read throughput for analytical queries given its columnar data storage format. Due to its columnar format, values for particular columns are aligned and stored together which provides
- Better compression
- Due to the very similar nature of the data stored side by side. All the column values are stored side by side, which in turn proves really helpful to the different compression algorithms as they perform much better with similar values to compress data from.
- Better throughput
- Analytics use cases mostly involved querying on particular dimensions which means with parquet we have the benefit of only extracting fields which are absolutely necessary for the query to execute. e.g. Select count(*) from parquet_files where student_name like “%martin%”. In this query, we will only extract the column student_name and save those precious IO cycles which were wasted in getting the rest of the unnecessary fields.
- Parquet also stores some metadata information for each of the row chunks which helps us avoid reading the whole block and save precious CPU cycles.
Understanding Parquet Layout
Before looking into the layout of the parquet file, let’s understand these terms.
- Row Group
- Column Chunk
- Data Page
- Dictionary Page
- Column Chunk
- Metadata Information

Row Groups
Parquet File is divided into smaller row groups. Each of these row groups contains a subset of rows. The numbers of rows in each of these row groups is governed by the block size specified by us in the ParquetWriter. ParquetWriter keeps on adding rows to a particular row group which is kept in memory. When this memory size crosses some threshold, we start flushing this in memory row groups to a file. So essentially these collections of rows which are flushed together constitute a row group.
Column Chunks
Each of these row groups contains a subset of the rows which are then stored in column chunks. Say the data we are writing to the parquet file contains 4 columns, then all the values of column1 for this subset of rows will be stored continuously followed by the values of column2 for this subset of rows and so

Data Page and Dictionary Page
Each of the column chunks is divided into data page and dictionary page. Dictionary Page is stored in case dictionary encoding is enabled.
In case dictionary encoding is enabled we store the keys in the dictionary and the references to these keys in dataColumns. On flushing, these references in the dataColumns get flushed onto the data pages and the actual keys in the dictionary get flushed onto the dictionary pages. In the case of dictionary encoding not being enabled, we store the actual data in these data columns instead of the references.

Parquet Metadata Information
Each parquet file contains some metadata information stored with it at the end of the parquet file i.e. footer. This metadata contains information regarding these things
- Row Groups References
- Column Chunk References inside of those Row Group References
- Dictionary Page References inside those column chunks
- Data Page References inside those column chunks
- Column Chunk Statistics
- Column Chunk Encodings
- Column Chunk Sizes
- Number of rows in the Row Group
- Size of the data in the Row Group
- Column Chunk References inside of those Row Group References
- Some Additional File Metadata
Writing to a Parquet File
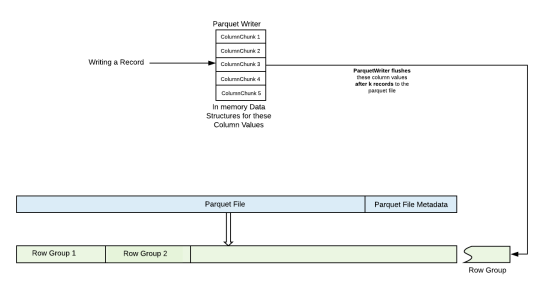
As we already explained in the previous sections, parquet stores data in the format of row chunks. These row chunks contain a group of records which are stored in the format of column chunks.
ParquetWriter maintains in memory column values for the last k records, so while writing a record to a parquet file, we often end up writing these values in memory. After memory limit exceeds for these maintained column values, we flush these values to the parquet file. All these records which were buffered in memory constitute a row group. This is done to save disk IOs and to improve write throughput.
Reading from a Parquet File
Before reading the records from the parquet file stream, we need to be aware of the layout of the file. By layout, we mean the following things
- Row Groups Offsets
- Column Chunks Offsets within those row groups
- Data Page and Dictionary Page Offsets
To know this layout, we first read the file metadata. This file metadata is always stored at a known offset in the file. After reading this file metadata, we infer the offsets for the different row groups and the different column chunks stored within those row groups. After getting these offsets, we can iterate over these row groups and column chunks to get the desired values.
Parquet File also offers the capability of filtering these row groups. This filtering for those row groups can be done via
- Filter Predicates
- These filter predicates are applied at job submission to see if they can be potentially used to drop entire row groups. This could help us save I/Os which could improve the application performance tremendously. These filter predicates are also applied during column assembly to drop individual records if any.
Examples described below
Filter Predicate: Filter all records which have the term "Sheldon"
for column 1
Row Group Dictionaries
Row-Group 1, Column 1 -> "1: Leonard, 2: Howard, 3: Raj"
Row-Group 2, Column 1 -> "1: Penny, 2: Amy, 3: Bernadette"
Row-Group 3, Column 1 -> "1: Stuart, 2: Memo, 3: Sheldon"
Now with the help of dictionary pages, we can easily filter out
the row groups which does not have the records which contain the
term "Sheldon" for column 1
Filter Predicate: Filter all records which have the rating > 50 Row Groups Row-Group 1, Column Rating -> (Min -> 20, Max -> 30) Row-Group 2, Column Rating -> (Min -> 45, Max -> 80) Row-Group 3, Column Rating -> (Min -> 40, Max -> 45) Now with the help of column page metadatas, we can easily filter out the row groups which does not records which have rating > 50.
- Metadata Filters
- With the help of metadata filters, you can filter out row groups by looking at their row group metadata fields. Eg. These filters involve filtering row groups via start and end offsets for these row groups. We can create a metadata filter which will make sure to filter the row groups which have the start and end offsets within an offset range.
- For more details see OffsetMetadataFilter, RangeMetadataFilter
See Next Blog Article for more details on various configurations provided by parquet for encoding your data.
References
- https://blog.cloudera.com/blog/2013/07/announcing-parquet-1-0-columnar-storage-for-hadoop/
- https://blog.twitter.com/engineering/en_us/a/2013/dremel-made-simple-with-parquet.html
- https://parquet.apache.org/documentation/latest/
- http://www.waitingforcode.com/apache-parquet/compression-parquet/read
- https://db-blog.web.cern.ch/blog/zbigniew-baranowski/2017-01-performance-comparison-different-file-formats-and-storage-engines
- https://www.slideshare.net/RyanBlue3/parquet-performance-tuning-the-missing-guide

Looks interesting.
I have a query where i loop the data on the dataframe based on certain conditions and write parquet format partition data which is failing with OOM exception. Unfortunately i cannot increase the memory due to some infra constraints. How can i effectively use the same memory to write the partition data and process the next partition.
LikeLike