Just a few days I was having this conversation with one of my colleagues. The conversation went as follows:
Me: Why we are going ahead with Design Y and not Design X even though the later design could improve the performance by a whole lot.
Friend: That was because implementing Design X meant that we had to support replication for fault tolerance. Also, replication seems to be one of the most challenging problems in computer science. So sadly, we went ahead with some sub-optimal design as we did not had any other choice.
Me: Hmm yeah, building replicated systems is really challenging.
In today’s world, we are building and designing systems at scale like never seen before. Every microservice that we build is either stateful or stateless. Now let’s talk a bit about these two kinds of microservices
Stateless Service
These services are somewhat easy to manage and scaling semantics are somewhat easy when compared to stateful services. We don’t need to worry about nodes going down or service becoming unserviceable because these services are stateless, so one can directly start using another node (serviceInstance).
Stateful Service
These services are somewhat challenging to manage because they have some state so we need to build these services considering the ramifications of nodes going down and service becoming unserviceable. So essentially, we need to make these service fault tolerant.
There might be two kinds of stateful services:
- Some Services serve as a cache in front of another stateful service, to guarantee better performance. These services do have a fallback, so fault tolerance is not that big of an issue for these services strictly from state loss perspective.
- Some other services do not have any fallback, so state which is present on the service is not present anywhere else. So we need to make sure that we provide durability, so that even if some nodes are down (up to a certain limit), there is no data/state loss.
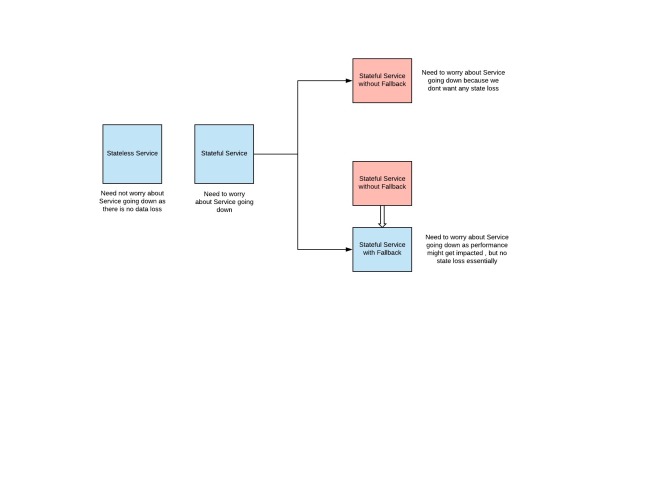
In the context of this blog, we are going to talk about how can we make sure that these stateful services without fallback remain fault tolerant.
Let’s first see how can we make these services fault-tolerant:
- Provide Replication Support in your Service
- This means that whenever you make a write request to one of your primary servers, make sure you send this write request to all the other replicas as well.
- One of the other solutions is to use have other open source solution or service which can help you out in your use case but that might involve a lot of changes in the source code of the open source solution
- Repurposing an open source solution to one’s use case is somewhat difficult because you need to understand the whole implementation and its intricate details. Also managing a different fork of the open source solution is often difficult.
- There might be some cloud-based solutions provided by different cloud service providers e.g DynamoDB, S3 or RDS by Amazon
- These solutions sometimes do not fit our use-cases as sometimes these cloud services (provided by cloud providers) cannot be repurposed for all of our use cases.
So essentially, we might need to build our own systems which have to support replication for availability.
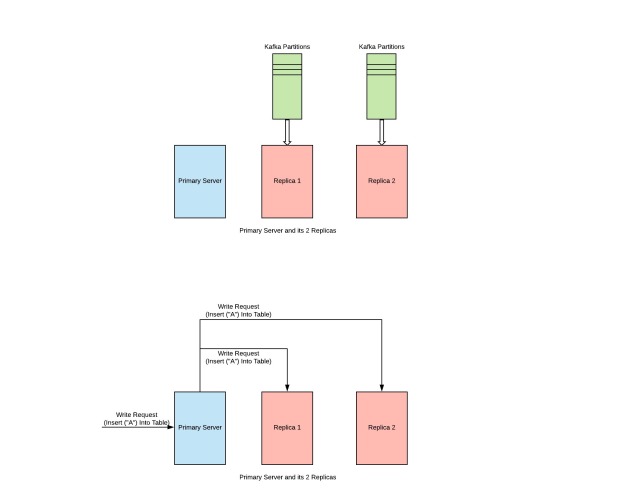
Question: So whats the big deal now, we just need to support replication which shouldn’t be that big of a deal, isn’t it?
Answer: You are totally mistaken here. Solving replication problem i.e. keeping two systems consistent is one challenging task. There is a whole bunch of literature just focussed on how can you make sure that two systems are in the same state aka replication. See this for more details.
A Brief Introduction to Replication
From Wikipedia,
Replication involves sharing information so as to ensure consistency between redundant resources, such as software or hardware components, to improve reliability, fault-tolerance, or accessibility.
There are two kinds of replication models:
- Synchronous Replication: This guarantee exactly same replicas at the expense of higher overhead for write calls to the primary server. This overhead would be because every replica would have its own latencies and all of these latencies would always come in critical path while making a WRITE REQUEST via the primary server.
- Asynchronous Replication: This guarantee better response time to writes but at the expense of availability, because there might be some data loss if the primary dies in between the two syncs. So some data which was there on primary and was not present on its replicas would be lost.

Both of these replication techniques have their downsides, as already said synchronous replication guarantees high availability and no data loss at the expense of higher WRITE latencies whereas asynchronous replication provides much better WRITE latencies on the expense lower number of network calls and batch syncs.
Note: Also, both of these techniques are not so straightforward to implement and need some deep understanding of the common pitfalls of the replication process in general. See this link for more details.
Kafka to the Rescue
Kafka is an open source stream processing system. We would be repurposing Kafka to solve our replication use case. As already told, replication is a challenging problem to implement unless you have had experiences with it before-hand at production scale.
Kafka provides these following guarantees which we will leverage to implement replication for our service.
- Exactly once Semantics while writing to the Kafka service
- Kafka Service makes sure along with Kafka client that all the writes made to the Kafka service are idempotent i.e. Kafka makes sure that there are no duplicate messages or no messages which are not committed.
- Ordered Delivery of Messages
- Kafka Service also makes sure that the messages written by producers in a particular order are also read in that particular order by the consumers.
- Atomic Updates to the partitions
- Kafka service also makes sure that you can write messages in an atomic fashion to multiple Kafka partitions. Read this for more details.
FYI: You need to have a bit of understanding of Kafka partitions to understand further. Read this to understand further around Kafka. If you don’t have time to go through the Kafka partitions, consider them as logical entities where producers write data and consumers read data in an orderly fashion and this partition is replicated across different nodes, so you need not worry about the fault tolerance of these partitions. Every data which is ever written to a Kafka partition is written at a particular offset and also while reading, consumer specifies the offset from which it wants to consumes the data.
Using Kafka to solve replication
Firstly, we need to make sure that we have one Kafka partition for every Replica for our primary server.
Eg. If you want to have 2 Replicas for every primary server, then you need to have 2 Kafka Partitions, one for each of these Replicas.
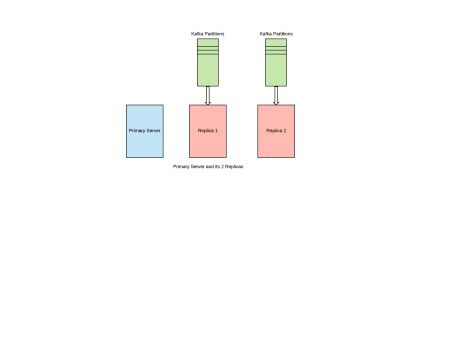
After we have this setup ready
- The primary server needs to make sure that for every WRITE Request made, apart from updating its internal state, it will also write these WRITE Requests to all the Kafka partitions belonging to the different replicas for this primary server itself.
- Every Kafka consumer running on those Replicas will make sure that it consumes all the WRITE Requests from the assigned Kafka partition and update its internal state corresponding to the WRITE Request.
- So eventually all these replicas will have the same state as of primary server.
Some of the replicas might be lagging behind but this might be because of some of the other systemic issues (which is not at all under our control) but eventually, all of the replicas will have the same state.
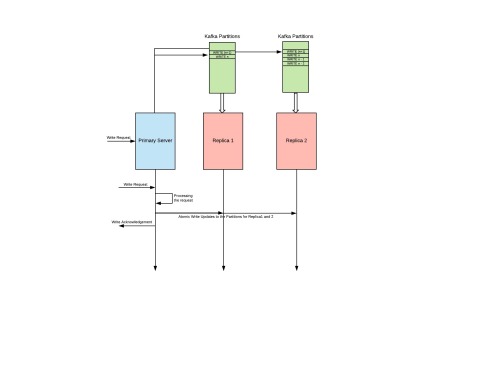
Implementation
One of the pros of this design is that it should not take many man-hours to implement. In this design, we need not worry about which replication do we want to use and what guarantees do we want to give in our system. This design should work out of the box for most of the systems.
Few things which we might need to implement in this design as well
- Mechanism to figure out which are the partitions associated with the replicas and if not already there, create and assign partitions to those replicas.
- After consuming the write request, making atomic updates to all of the replica partitions. Kafka already exposes APIs for making atomic updates to multiple partitions.
- Reading at a particular offset from Kafka. This should be a really minimal task, as there are many open source libraries (or code segments) which will do the same stuff for you.
Now let’s discuss the positive points of this design
- We can easily guarantee eventual consistency with this design, but if you want monotonic consistency, then that can be achieved by making sure that reads are always served by the last updated replica (or by most lagging replica in terms of updates) and this can be easily figured out by checking the uncommitted offsets for all of these replica’s Kafka partitions.

- High Write throughput for most of the requests on Kafka cluster, see this for more details. Also in most of the benchmarks done, it seems Kafka provides single digit latencies for most of the requests. Let’s look at down into the request latencies
Old_Request_Latency = PWT_1 + PWT_2 + ....... + PWT_n New_Request_Latency = PWT_1 + KWT_2 + .... + KWT_n where PWT_1 = Time taken to process request on Node 1 PWT_2 = Time taken to process request on Node 2 and so on KWT_2 = Time taken to write requst to kafka partition for replica 2 KWT_3 = Time taken to write requst to kafka partition for replica 3 and so on Old_Request_Latency encapsulated writing requests to all of the available replicas. New_Request_Latency includes writing request to one of the primary servers and making sure the write request is written on all the concerned partitions
Essentially latencies cannot be compared between these two subsystems, but having said that as there is an extra hop for introducing Kafka, there would be some additional overhead which should be really minimal considering latencies of Kafka.
- If one of the replicas is having high latencies at some moment (because of high GC pauses or disk being slow), then that could increase latencies for the WRITE requests in general. But in our case using Kafka, we can easily get over this issue as we would just be adding the WRITE REQUEST to the REPLICA’S KAFKA PARTITION so it would be the responsibility of the REPLICA to sync itself whenever it has some CPU cycles.
Apart from these pros, there are obviously some cons in this design as well.
- Although Kafka gives higher write throughput for the majority of the requests, there will be an additional overhead of adding another network hop 😦 in this design. The impact should be really less of adding Kafka because Kafka is really sensitive towards WRITE latencies but still there would be some impact nonetheless.
Note: Write latencies for smaller payloads would increase by a higher percentage when compared to latencies for bigger payloads. This is because of the majority of the time for smaller payloads is spent on the network roundTrip and if we increase the number of network roundTrips, then this time is bound to increase. So if we can batch the write requests into a single write request and then write it to a Kafka partition, then the overhead of this approach should be really minimal.
Also, there is one important optimization that we can do in this current design to improve the write latency.
In the current design, we have N Kafka partitions for these n replicas. What if we have only single Kafka partition for all of these n replicas, then we will have better write throughput as we need not make write request to every Kafka partition (n Kafka partitions in total). The only requirement is that all of these n Kafka consumers (running on n different replicas) should belong to different consumer groups because Kafka does not allow any two consumers of a single consumer group to consume the same KTP.
So having these n kafka consumers each belonging to n different consumer groups, should improve the write throughput and latency as these n kafka consumers will read the WRITE Requests from a single KTP.

References:
- https://kafka.apache.org/
- https://en.wikipedia.org/wiki/Replication_(computing)
- https://sookocheff.com/post/kafka/kafka-in-a-nutshell/
- https://www.confluent.io/blog/how-to-choose-the-number-of-topicspartitions-in-a-kafka-cluster/
- https://www.confluent.io/blog/exactly-once-semantics-are-possible-heres-how-apache-kafka-does-it/
- https://searchdisasterrecovery.techtarget.com/

2 thoughts on “Building Replicated Distributed Systems with Kafka”