One of the core security features of the modern operating system is to provide isolation between the different processes running on a system and make sure that one process should not be able to see the data used by another process. In our current ecosystem, we often have multiple VMs running as different processes on a single machine, assuming one might be a victim and other might be an attacker, so we need this process isolation more than ever.
We already know from our previous blog post that this isolation in modern processors is provided by privilege levels. A process running with a lower privilege level i.e. user process does not have access to the memory region having higher privileges i.e. kernel memory
With Meltdown vulnerability, this security feature breaks down in crumbles. With Meltdown, a process can now access kernel memory which might contain certain pieces of critical data about other processes. Meltdown uses a combination of flush reload attack and speculative execution to melt these boundaries between kernel and user process.
Understanding Meltdown
Meltdown works on the core concepts of speculative execution and flush-reload attack. Speculative execution gives us the liberty to allow an instruction to execute even though the previous instructions execution has not completed. We exploit this behavior of modern processors to execute some instructions which would not have been executed otherwise. There are two parts of this
- Transmitting the secret from kernel memory to CPU Cache via Speculative Execution
- Receiving the secret from CPU cache to User Memory via Flush-Reload Attack
Let’s take this code example which will bring the secret information stored from kernel memory to CPU cache.
uint8_t p = *(uint8_t*)(kernel_address); uint8_t val = probe_array[p * 4096];
In the above example, we are essentially trying to access this memory location at kernel_address ( into a variable p ) from a userspace program. After this first statement, we are trying to access some contents of a large probe_array at an offset of ( p * 4096 ).
So when we will execute this code, ideally we should receive a segmentation fault while executing the first command itself due to invalid access. But due to speculative execution, whilst we are executing the first command itself, the processor starts with the execution of the second instruction.
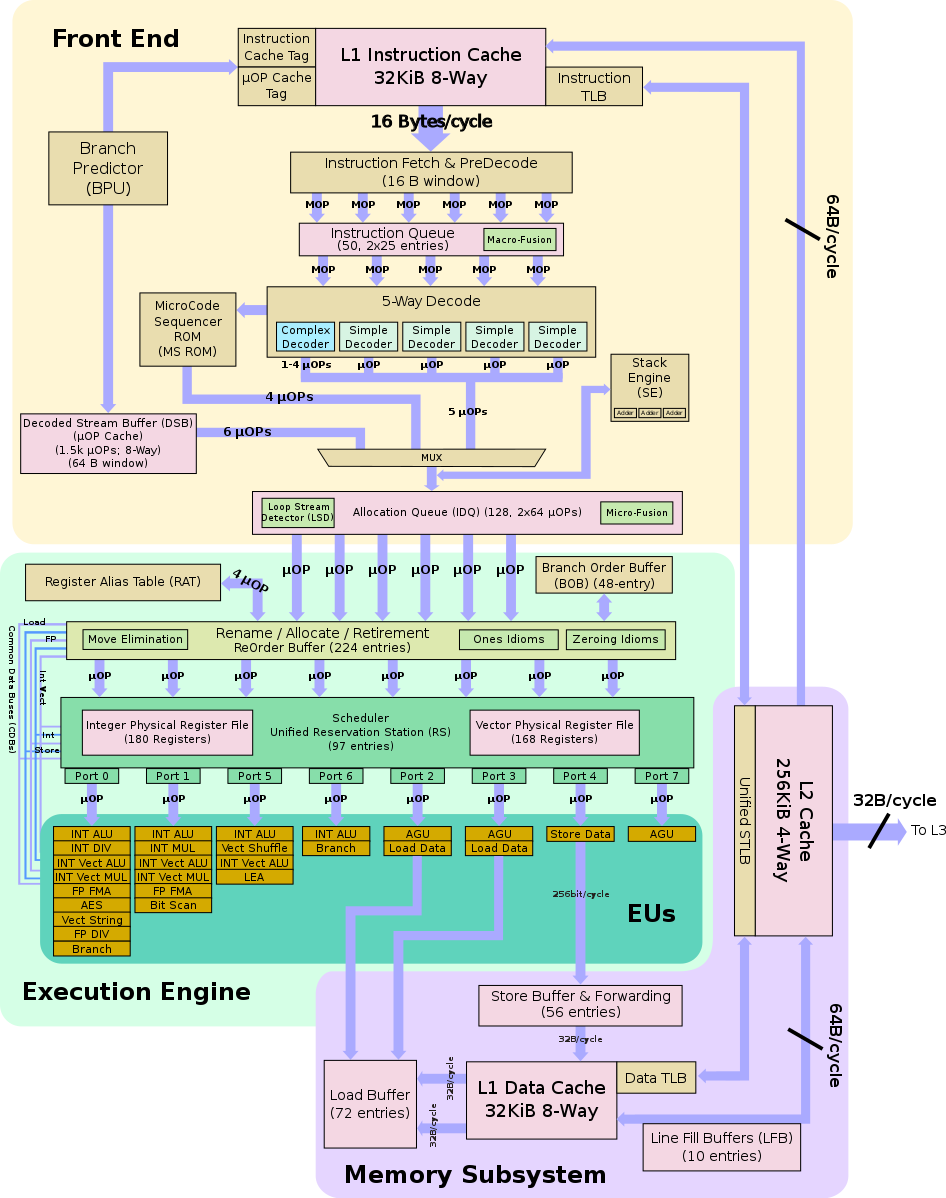
Every instruction given to the processor for execution is broken down into a sequence of µOP. These µOPs are a basic unit of execution on modern Intel processors. There can be multiple µOPs running simultaneously on a single processor. If any of the µOPs in this speculative execution window gets errored out ( i.e. exception or something else ), then all the subsequent instruction or µOPs are retired and their state is cleared from the registers.
So here is the sequence of events which happens
- Before starting the instructions, we will make sure that we have flushed out all the contents of the probe_array and there is no entry of probe_array in CPU cache.
- The processor starts with the instruction for reading the memory contents from kernel_address.
- When the kernel address is loaded in statement 1, it is likely that the CPU already issued the subsequent instructions ( i.e. p*4096 and probe_array[p * 4096]) as part of the speculative execution, and that their corresponding µOPs wait in the reservation station for the content of the kernel address to arrive. As soon as the fetched data ( i.e. value stored at kernel_address ) is observed on the common data bus, the µOPs can begin their execution.
- Now when these µOPs finish their execution, they retire in order and checked for possible exceptions in order. So as in this case our first statement i.e. loading kernel address throws an exception, so the pipeline is flushed to eliminate all the results for the instructions which were executed speculatively. In this way, we throw away the computations done speculatively which otherwise would not have been executed at all.
- Now let’s take this instruction accessing probe_array[p * 4096]. We know that during the execution of the above µOPs in the speculation window, we would have loaded this value in some physical register and the processor would have thrown away the results for this knowing that memory lookup at kernel_address was illegal. But when we would have loaded probe_array[p * 4096] from memory to register, there we ( processor ) would have been some changes in the cache state and this value would have been loaded in the cache.
- So at the end of this speculation window (after making illegal access to kernel_address), the only change we made to the CPU Cache state is that value at probe_array[p * 4096] will now be cached ( because step 1 flushes out all the values for probe_array )
- Now we will iterate over all the possible values of p i.e. from 1 to 256 and for each value of p, we will check if probe_array[p * 4096] is cached or not. This can be done easily via some of the learnings from the previous blog post on flush reload attack.
- If it is cached, then we have identified the value of p, otherwise, we will keep on iterating until we found such p.
Note: This value of 4096 or 4KB has been chosen to ensure that there is a large spatial distance between any two values of p so that hardware prefetcher does not cache some other addresses of probe_array into L1 or L2 cache corresponding to some other values of p which might result into fuzzy results.
Dealing with this Meltdown Vulnerability
This vulnerability can be used to attack any system running on cloud platforms which share resources with other systems. Even our standalone desktops and laptops are also at risk, because of browsers and javascript. Javascript allows websites to run custom code to run on our system.
So we need to mitigate Meltdown ASAP. Here are some of the mitigation techniques employed by the operating system vendors.
Kernel Page Table Isolation ( employed by Linux Kernel )
We already know from the previous blog post that kernel memory and user memory are mapped into a single page table. Although the access to the contents of kernel memory is prohibited in user mode because of lower privilege level, still they are mapped into a single page table. As both kernel memory and user memory is mapped into a single page table, so user process is able to speculatively get a hold of the values stored in the kernel memory ( which we just read about ).
This mapping of both kernel memory and user memory in a single page table is essential because when we make a system call, then we need not load new page table for kernel page table entries into TLB as well as CR3 register.
Kernel page Table Isolation proposes to segregate the kernel page entries from the user process page table. So when a process is running in user mode ( lower privilege mode ), then it has no access whatsoever to any of the kernel page entries ( barring few entries which are essential ). But when a process makes a system call, then in this kernel mode, the kernel will have access to all the page table entries of the kernel + process.
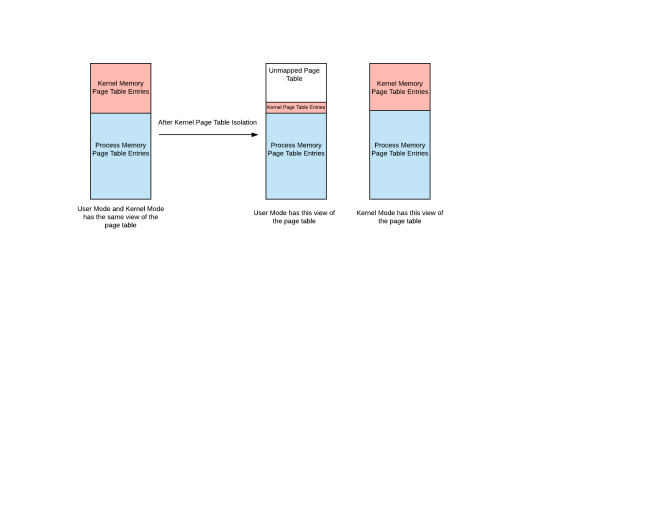
While executing in kernel mode ( privileged mode ), it is necessary to have the page table entries for user process as well because nature of the system call might be such that we kernel might need to copy some data from kernel memory to user memory which would be possible only when we have user + kernel page table entries visible while executing in privileged mode.
Read this for more details about kernel page table isolation.
References:
- https://meltdownattack.com/meltdown.pdf
- https://lwn.net/Articles/741878/
- https://medium.com/@mattklein123/meltdown-spectre-explained-6bc8634cc0c2
- https://en.wikipedia.org/wiki/Speculative_execution
- https://defuse.ca/flush-reload-side-channel.htm
- http://www.goodmath.org/
- https://rwc.iacr.org/2018/Slides/Horn.pdf

http://dkjshye7s632.com
That is the right blog for anyone who wants to seek out out about this topic. You understand a lot its virtually laborious to argue with you (not that I really would need…HaHa). You positively put a brand new spin on a subject thats been written about for years. Nice stuff, simply great!
LikeLike
http://dkjshye7s632.com
Spot on with this write-up, I truly think this website needs much more consideration. I’ll in all probability be once more to learn much more, thanks for that info.
LikeLike
With havin so much content do you ever run into any issues of plagorism or copyright infringement?
My blog has a lot of exclusive content I’ve either authored myself or outsourced but it seems
a lot of it is popping it up all over the internet without my agreement.
Do you know any ways to help prevent content from being stolen? I’d certainly appreciate it.
LikeLike
I really like your blog.. very nice colors & theme.
Did you design this website yourself or did you hire someone to do it for you?
Plz respond as I’m looking to construct my own blog and would like to know where u got this
from. many thanks
LikeLike
I am mostly using wordpress themes. Hope that answers your question
LikeLike